
TL;DR
At Eightfold, we’ve built a state-of-the-art system (SOTA) for matching people to jobs. What makes it SOTA is that the matching system goes far beyond keyword matching. It uses deep semantic understanding of people and roles coupled with low-latency machine learning models to match candidates to jobs holistically, capturing not just their accomplishments but their potential.
Problem: Talent matching lacks semantics, fairness, and scale
Traditional matching systems lean heavily on keyword overlap. But job titles vary, skills are inconsistent, and resumes rarely capture a person’s full trajectory. Matching by surface-level text leaves too much value on the table.
As an engineer on the AI Platform team, I work on the core system that powers matching across our products. We designed this system to move beyond keyword search and towards a deeper, fairer understanding of people and roles, ensuring explainability in every match.
Solution: A novel AI-powered talent matching solution
Eightfold’s Match Score distinguishes itself by offering superior fairness and accuracy in matching people to roles that could otherwise be missed by both sides (candidate, hiring manager), thereby opening the door to powerful new alliances and opportunities. Our models are specifically trained on vast talent datasets, ensuring precise candidate-job matching. Fairness is intrinsically designed into the system to mitigate biases that could disadvantage underrepresented groups. This approach results in consistently high accuracy in hiring decisions, making it a more dependable and secure option. As highlighted in our recent blog post, Eightfold’s Match Score is a purpose-built model comprising a wide array of techniques delivering superior accuracy and fairness, instead of relying solely on LLM-powered inferencing. This post will delve into the complex algorithms of the platform’s matching engine, explaining how it calculates fair and comprehensive match scores. We break it down into three steps:
- Step 1: Extract deep semantic embeddings from unstructured data
- Step 2: Add interpretable features from deep structured extraction
- Step 3: Perform fast explainable inference of match scores
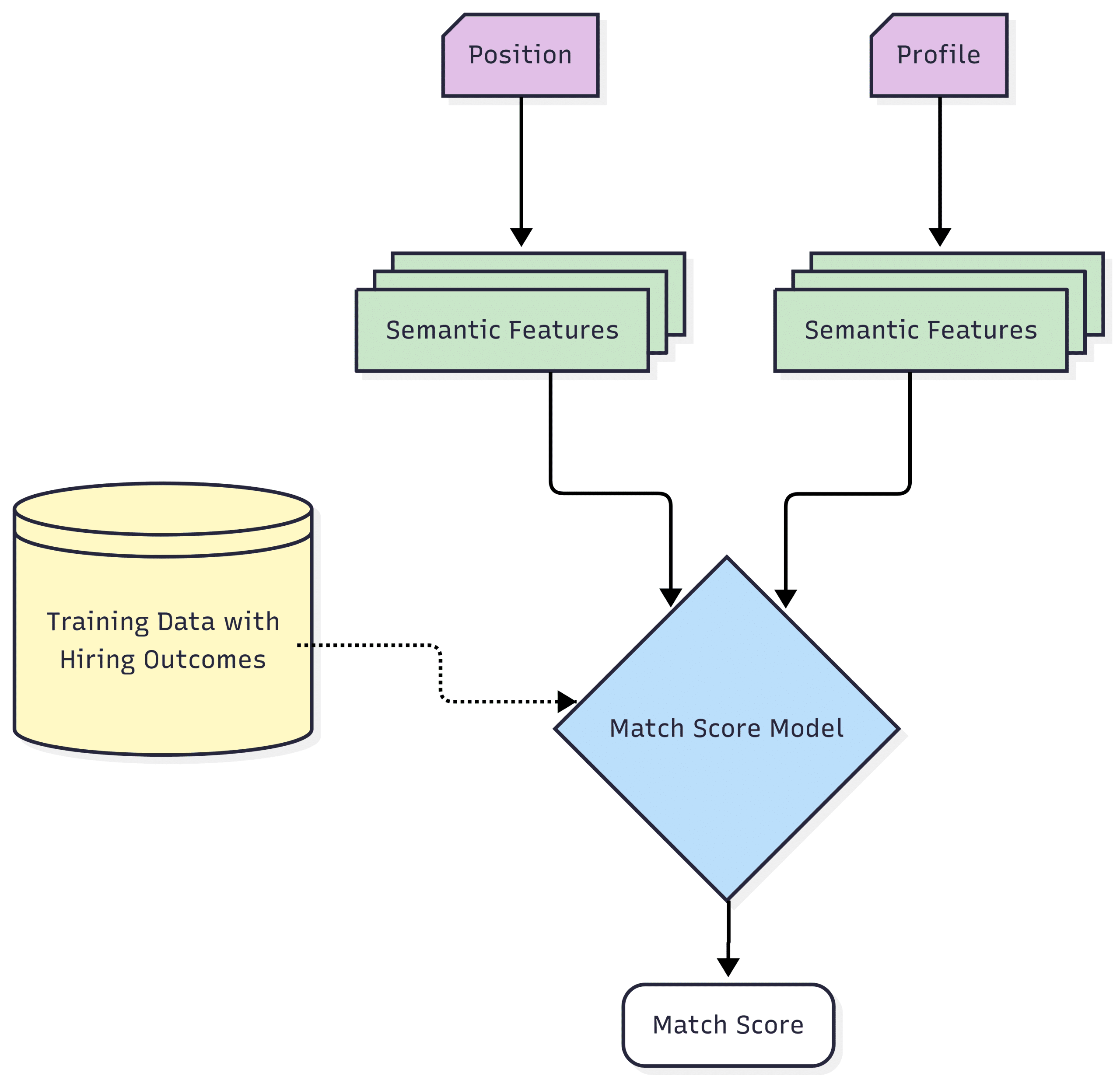
Let us go into further detail on each step.
Step 1: Extract deep semantic embeddings from unstructured data
We start with embeddings at a high level. Every resume and job description is embedded into a high-dimensional vector space. These vectors come from pretrained language models, then processed with dimensionality reduction models trained on our talent datasets.
For this, we have experimented with a variety of pre-trained LLMs, and picked the ones that work best. This yields deep semantic embeddings for both people and jobs.
By encoding context into the vector itself, we can compute similarity in a way that captures meaning beyond just words. For example, we can detect that “Machine Learning Engineer at a fintech company” profile and “Data Scientist at an insurance firm” profile may have similar functional capabilities, even if the titles, experiences and industries differ.
This forms the foundation of semantic understanding across our platform.
Step 2: Add interpretable features from deep structured extraction
Embeddings are powerful, but they don’t represent the full spectrum of context we need to capture from user profiles and jobs, nor are they easily interpretable. To account for these two factors, we extract additional sets of rich features from the structures fields of profiles and jobs, including:
- Skill overlap
- Title progression and seniority fit
- Industry and company similarity
- Context of ideal candidates and hiring manager
Let’s dive deeper into what these mean and how we efficiently compute these features using our token embedding models. We embed skills, titles, companies, degrees, and schools using token-level embedding models. We have trained token-level embedding models on hundreds of millions of internal profile and job-text tokens and continuously refresh them.
Skill Overlap
Each unique skill phrase (e.g., “React”, “Kubernetes”, “Financial Modeling”) is mapped to an N-dimensional vector. Closely related skills land near one another in this space – “Pandas” lands closer to “Python” than to “Panda”.
Skill-based measurement
This measures the cosine similarity between a job’s overall skill vector and a candidate’s complete skill vector. This value indicates broad alignment, showing if a candidate has ever used or listed the required technologies.
Recent skill-based measurement
This calculates the cosine similarity between a job’s skill vector and a candidate’s skill vector, but only using skills from their most recent experiences. This prioritizes recent skill usage, differentiating between someone who used a skill eight years ago and someone using it currently. This recency adds a “freshness” dimension to candidate ranking and helps recruiters assess how current a skill set is.
Together, these two ways of looking at skills provide a quick, interpretable signal of “does the candidate know the skills” and “have they used them lately,” forming a robust foundation for deeper scoring.
Title progression and seniority fit
The first question recruiters implicitly ask is: “Has this person held—or can they plausibly transition into—the title I’m hiring for?”
Our engine answers it with complementary metrics derived from token level similarity and recency logic. We embed titles into N-dimensional vectors using token embedding models and use them for downstream computations.
To start with, let’s talk about the current title similarity and then we’ll dive deeper into how we model a candidate’s past experiences and its similarity with the hiring position’s title.
Current title similarity
Think of this as the answer to a plain-English question: “How close is this person’s job title right now to the title I’m hiring for?”
Here’s how it feels in everyday terms:
- Same Seat, Same Team → Score ≈ higher range. Hiring for: “Senior Backend Engineer”. Candidate’s current title: “Backend Engineer”. They’re already doing virtually the same job today.
- Close Neighbour → Score ≈ mid-range. Hiring for: “Product Manager”. Candidate’s current title: “Product Owner”. Overlapping responsibilities; minimal re-orientation needed.
- Distant Cousin → Score ≈ lower-range. Hiring for: “Data Scientist”. Candidate’s current title: “Business Analyst”. Some analytical overlap, but would require skill ramp-up.
But here’s the catch. While current title similarity starts with the candidate’s published title(s), we also ask: “If their career keeps following its current trajectory, what title are they statistically most likely to hold next?”
To solve this problem, we use Recurrent Neural Networks (RNNs) to model career trajectories over hundreds of millions of samples and use them to predict the next title of a candidate given their past experiences. A recurrent model ingests the sequence of a person’s past titles, skills, and tenure durations and outputs a next-title vector—our best guess of their upcoming role in the vector space. Example: someone who has moved from “Support Engineer” → “QA Engineer” → “Backend Engineer” has a high likelihood of assuming a title of “Senior Backend Engineer” next.
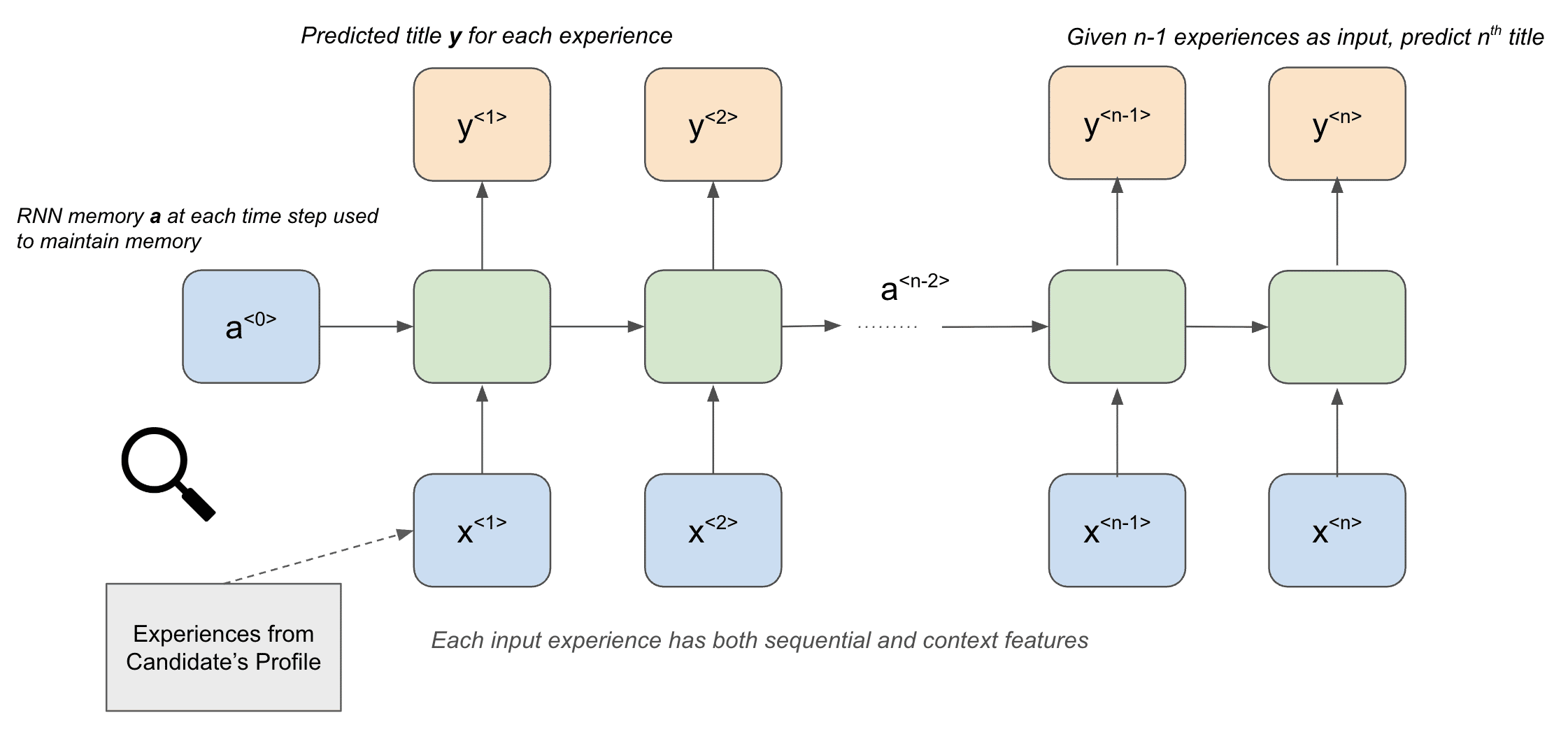
We then compute the cosine similarity of this vector with the hiring title of the position and use it to improve the current title similarity computation logic, which is used as a signal in the downstream inference step.
In the next section, we will also discuss how we use RNNs to predict the next company/work of a person and use it downstream.
Industry and Company Similarity
Titles tell what someone does; work history reveals where they have done it and where they might head next. To start with, we embed the employer name (candidate and position) into the same token-level vector space used elsewhere using our token embedders trained to embed companies. For example, the vector for “Google” lands almost on top of “Microsoft,” a few steps from “Amazon Web Services,” but miles away from “KFC.” In the same vein, “Goldman Sachs” clusters tightly with “JPMorgan Chase,” while both sit far from “Spotify.” Now, let’s dive deeper into how we infer and compute company-related features.
Company Similarity
Company similarity is our shorthand for answering: “Has this person spent their recent career in companies that look and feel like the ones this role values?” To make this inference, each employer name is embedded into an N-dimensional vector. This is followed by a cosine similarity computation between the companies a candidate has worked for and the companies associated with the role of interest.
Hireability
When recruiters browse profiles, two silent questions arise:
1) “Has this person been at similar kinds of companies?” (answered by company similarity explained above)
2) “Will they join a company like ours next?” – That’s what hireability measures, and we’ll explain how we use that in our engine.
To infer hireability, we again use RNNs (explained above in the title section) to feed the sequence of past employers and model outputs a next-company embedding—an N-dimensional vector representing the organisation the candidate is most likely to join on their next move. We have trained this model on our internal dataset of hundreds of millions of career trajectories. For example, if a candidate has worked as a “Software Engineer at Shopify” and then transitioned to “Senior Software Engineer at Stripe”, they are most likely to transition into a SaaS tech company like Google, Microsoft, or AWS rather than working as a “Senior Software Engineer at Starbucks” or Intel.
This embedding is used solely to compute similarity with the hiring company’s embedding and serves as a core feature downstream.
Match with ideal candidates and the hiring manager
Even when a job posting is sparse or ambiguous, star performers on the current team or similar teams, or even past employees on the team, give us a hint and context of who might excel at the role. This is a handful of “successful” past or internal hires. By measuring how close each applicant is to the objective factors shown by those reference profiles, like skills, the engine gains a strong, human-grounded signal. We expose these fields to the recruiter, allowing them to add them and guide the matching engine towards their desired results.
For each participant (candidate, similar candidate, hiring manager), we generate dense embeddings of skills, titles, past companies, and experiences. These embeddings are then used to calculate similarity between the candidate’s profile and reference profiles (ideal candidates and hiring manager) across these attributes.
While embeddings are valuable and hold strong signals, incorporating some objective scalar signals into the matching model is crucial for a truly comprehensive evaluation. These signals let us model real-world hiring preferences. A strong match might mean the person doesn’t have every listed skill, title, or company, but their trajectory and experience point to success in the role. Let’s see how we combine all these features together to evaluate and score a candidate holistically using our machine learning models.
As a side note, we also have a system that can automatically find ideal candidates for a position based on past hiring decisions of similar positions. We’ll cover that in a future blog.
Step 3: Perform fast, explainable inference of match scores
Once we’ve extracted hundreds of features—embeddings, similarities, structured data—we blend them into a calibrated prediction. This model helps us rank candidates by likelihood of success, using historical data on who applied, got advanced, who was hired, and who thrived in similar roles. The model is trained on real-world hiring outcomes to predict probabilities.
The model is trained on more than tens of millions of historical candidate-position pairs with known outcomes, using features extracted at the time of the original interaction.
The score is then scaled between 0 and 5 and rounded to half-point intervals in order to be displayed as star ratings in the product for a profile against a position. This formula ensures that candidates who are likely to engage and succeed at securing the job rank high, while others rank lower. The result is a single, well-calibrated score that balances a large set of signals—from word vectors to career trajectories—into a ranking that the hiring team can trust and act on.
Putting things together, this is a 30,000-foot view into our matching system.
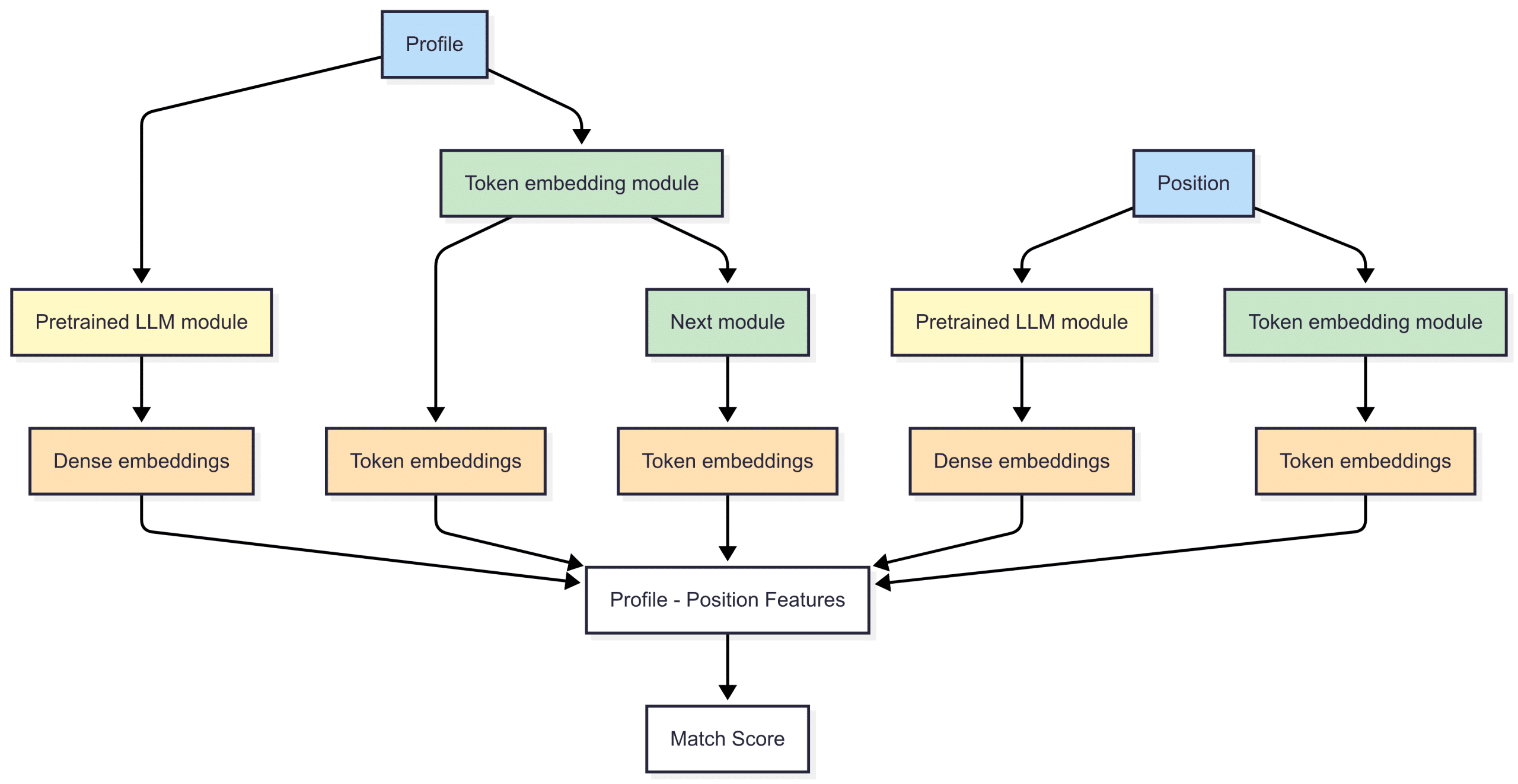
What makes our approach different
Many systems use embeddings. Few combine them with rich real-world features. Even fewer continuously retrain based on recruiter behavior, hiring outcomes, and evolving workforce signals.
Our system is:
- Context-aware: Skills are interpreted differently based on role, level, and company type
- Flexible: Hiring managers or Recruiters can upload ideal candidate profiles and influence the matching logic
- Explainable: Matching explanations can be surfaced to support recruiter decisions
This hybrid approach gives us both depth and adaptability. It mirrors how experienced recruiters think, but at scale.
Why it matters
Matching isn’t about finding perfect resumes. It’s about recognizing potential in imperfect ones. By combining semantic understanding with structured reasoning, we’ve built a system that sees beyond the text and into what truly matters.
If you’re curious to explore how this works in production or want to help shape what comes next, there’s more coming soon.
Read more technical deep-dives on our Eightfold Engineering blog and explore open roles on our team.