
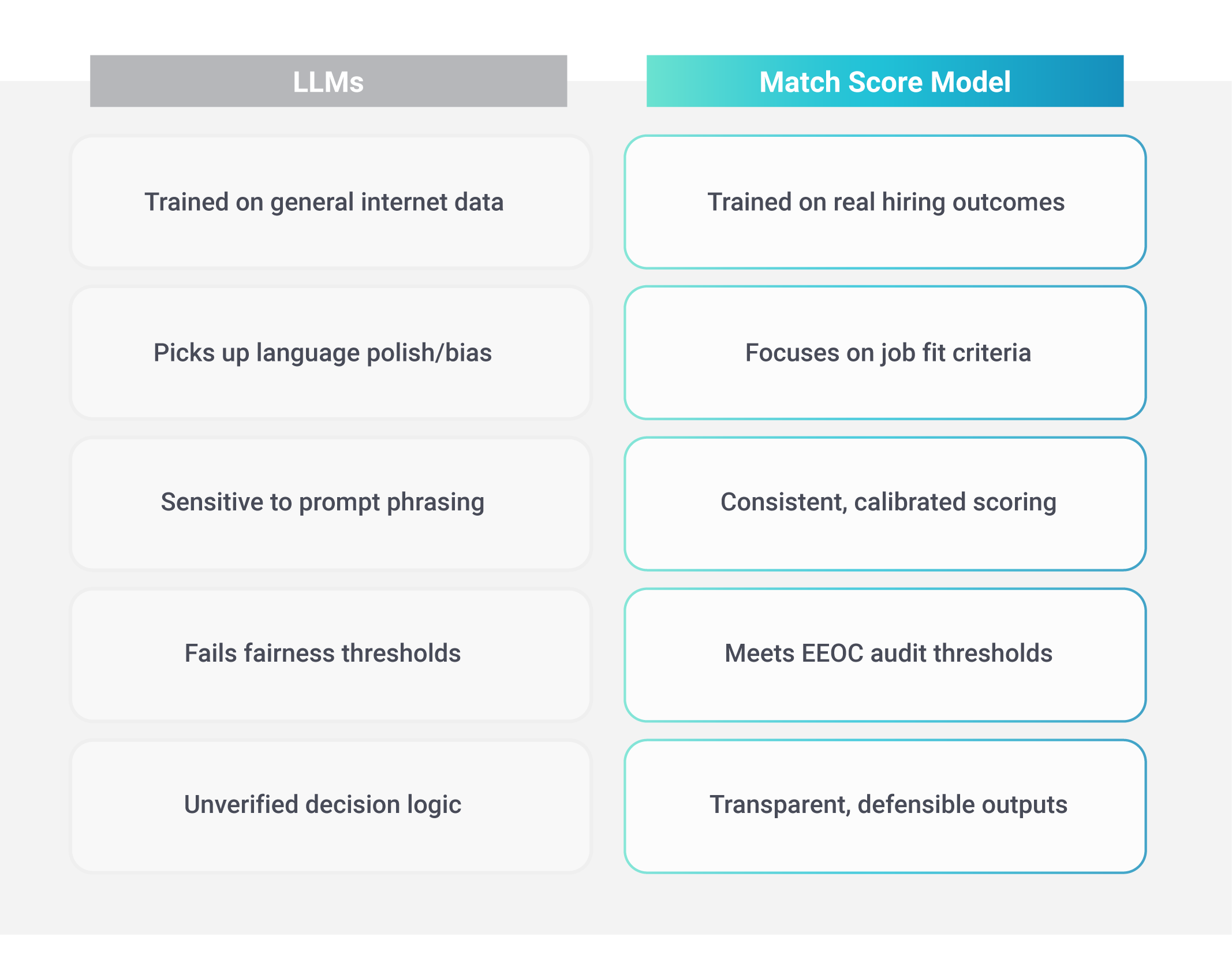
- General-purpose LLMs, like GPT-4 and Claude, aren’t trained to deliver hiring outcomes, which limits these tools’ accuracy in predicting candidate-job matches.
- Fairness isn’t baked into general-purpose LLMs, and our study found they can systematically underserve underrepresented groups.
- A purpose-built model, like Eightfold Match Score, delivers superior accuracy and fairness, making it the safe choice for hiring decisions.
General-purpose large language models (LLMs) like GPT-4 and Claude are powerful. These tools can summarize articles, write code, and even reason.
But does that make these LLMs suitable for hiring decisions?
Our latest research, “Evaluating the promise and pitfalls of LLMs in hiring decisions,” shows the answer is not without significant risks.
We tested how well general-purpose LLMs match candidates to jobs by comparing these tools to our specialized Match Score model. Using 10,000 real candidate-job pairs, we stripped personal details from résumés, standardized the data, and asked each model to rate the match. We then measured each model’s accuracy in ranking candidates and its fairness in treating underrepresented groups.
Our findings showed our domain-specific Match Score model — which also includes hiring outcomes data across organizations, industries, roles, and languages — achieves superior predictive accuracy and more equitable outcomes across diverse demographic groups, outperforming top general-purpose LLMs on every metric.
But there’s even more to the story. Let’s break down our findings with these takeaways.
[Ed’s note: While Eightfold Match Score includes its own custom LLM, for the sake of clarity in this article, LLM will refer only to general-purpose LLMs used in the study.]
Related content: Explore the crucial impact of AI in hiring decisions, from candidate screening to talent acquisition.
LLMs aren’t trained on hiring outcomes
General-purpose LLMs are trained on enormous amounts of text from the internet — everything from Reddit posts and Wikipedia articles, to books and news stories. This breadth gives LLMs incredible general knowledge and language understanding that is still evolving.
But here’s the catch: general-purpose LLMs have never been trained on hiring outcomes.
That means while these models have “read” résumés, job descriptions, and even career advice, general-purpose LLMs have never been taught what a successful hire looks like. These models are less adept at distinguishing between a candidate who was hired, one who only made it to the interview stage, or one who was rejected.
In contrast, the purpose-built Eightfold Match Score model is trained on:
- Real résumés with verified skills, experiences, and qualifications.
- Real job descriptions reflecting actual role requirements across industries.
- Real outcomes, such as data indicating which candidates got interviews, offers, or hires.
Fine-tuned models, like Match Score, have task-specific feedback baked in. General-purpose LLMs don’t, and that differentiator is critical.
LLMs are not optimized for fairness
A critical misunderstanding in applying general-purpose LLMs to hiring is the assumption that these models will be inherently fair. These are not — and that’s because fairness isn’t part of what these models are optimized to do.
General-purpose LLMs, like GPT-4, Claude, and Gemini, are trained to be fluent, useful, and safe — not fair decision-makers. These models primary objective is to predict the next word in a sentence, based on patterns learned from massive internet-scale datasets, and the results delivered can vary based on the prompt given.
While fine-tuning steps like reinforcement learning from human feedback are applied to make general-purpose LLMs more helpful or less toxic, those steps don’t teach these models how to avoid bias in structured decision-making.
In hiring, fairness isn’t a byproduct — it’s a requirement.
A model can sound inclusive while still reinforcing inequities behind the scenes. For example, it may favor polished résumés or elite institutions, even if those aren’t the best predictors of job success. It may also replicate subtle language-based signals that correlate with race, gender, or socioeconomic status — without even “knowing” it’s doing so.
Because general-purpose LLMs aren’t trained on labeled hiring outcomes or explicitly penalized for demographic bias, these have no mechanism to learn equitable treatment. LLMs reflect the world as it is, not how it should be.
In contrast, purpose-built hiring models, like Match Score, are trained with fairness objectives in mind. These models are explicitly evaluated and optimized for equitable outcomes across race, gender, and intersectional groups.
Fairness isn’t an afterthought — it’s engineered into the core.

Here is how Eightfold Match Score measures against general-purpose LLMs in fairness metrics.
Fairness metrics fall short using LLMs
Digging deeper into the metrics behind fairness was one of the most important findings from our research. General-purpose LLMs, when unmodified, show significant fairness gaps — particularly across intersectional dimensions — due to training on uncurated public information.
For example:
- The best general-purpose LLM we tested had a lowest intersectional impact ratio (IR) of 0.773.
- Our custom-built Match Score model achieved an IR of 0.906, a much narrower gap.
In practical terms, this means that even when general-purpose LLMs are close on overall accuracy, these can systematically under-score candidates from certain minority groups. This happens because general-purpose LLMs reflect the biases present in the vast, uncurated internet text they’re trained on or based on the prompt given.
Even if you mask names or remove explicit gender markers, general-purpose LLMs identify details like certain schools, job titles, or even sentence structure that can correlate with demographic attributes.
Fairness isn’t a nice-to-have — it’s critical. Bias mitigation must be baked into the model your recruiters use.

Why a purpose-built model matters
While it might seem logical that a purpose-built model would outperform a general-purpose LLM, additional findings in our research show that it’s not only a matter of performance.
It’s about the deep risks of relying on general-purpose LLMs in high-stakes decisions like hiring.
When we talk about AI in hiring, it’s not just about getting good results. It’s about getting fair, consistent, and auditable results that support your business case, are easy to audit, and build trust with hiring managers.
In high-stakes areas like hiring, where decisions impact people’s lives and livelihoods, “good enough” isn’t enough. The fairness and accuracy provided by a purpose-built, domain-specific model isn’t just better — it’s essential to the hiring process.
Read the full research paper, “Evaluating the promise and pitfalls of LLMs in hiring decisions.”
Varun Kacholia is CTO and Co-founder of Eightfold AI.











