

TL;DR
While much of the industry is working to turn prototype agents into reliable products, Eightfold’s AI Interviewer is today a production-grade, secure, compliant, multimodal, multilingual system that conducts candidate interviews at scale. This article focuses on the fairness of that deployed agent, specifically with respect to race and gender.
Eightfold rigorously tested whether the underlying AI model treats candidates fairly across protected attributes such as gender and race. Using advanced synthetic testing, we ran interviews at scale where we systematically varied the candidate’s race and gender. Across many test cases, all interview metrics, including quality, feedback accuracy and scoring, remained virtually identical. Differences found were under 1%, well within expected model noise. In short, Eightfold’s AI Interviewer treats candidates across races and genders fairly and scores the interviews consistently regardless of their race and gender.
Introduction
AI Interviewer is Eightfold’s production system for conducting candidate interviews. It is designed to augment hiring processes and help recruiters and hiring managers conduct and analyze interviews more efficiently, in a secure and compliant enterprise environment. AI Interviewer asks structured, role-specific questions, captures and summarizes responses, and fills out a standardized evaluation form. It also assesses how well each candidate’s responses and experience align with the requirements of the job.
Eightold believes any AI system that assists in helping make hiring decisions needs to be fair to unchangeable, irrelevant attributes of each candidate, such as race and gender. To make sure candidates across protected categories are treated fairly by the AI model, Eightfold tests the AI Interviewer for potential bias. This involves checking whether demographic attributes, such as gender or race, influence how it conducts or scores interviews. The goal is to confirm that AI Interviewer assessments are driven by how the candidate’s interview answers reflect their skills, experiences and education required for the role.
Experiments
For the experiments below, we specifically evaluated the impact of gender and race. Synthetic candidate profiles were created to represent an applicant pool of gender and racially diverse applicants. Each profile was slightly modified to test whether changing the protected attributes of race and gender affected the outcomes. For example, a name which is generally male was changed to a predominantly female name, or racial identifiers were varied across common demographic groups. Both the original and modified candidates completed AI based Interview sessions under an identical setup. Each run used the same interview plan—meaning the same sequence of stages, topics, and question templates—plus the same evaluation framework. Neither the interview plan configuration nor the scoring criteria changed across sessions.
Samples
Sample for gender perturbation

Interview metric definitions
Interview quality metrics
These metrics show how well the AI Interviewer manages the conversation. Higher scores are better unless noted otherwise.
- Interview Coverage Score: Measures whether all planned questions from the interview guide were covered.
- Question Clarity Score: Checks if the agent phrased questions clearly and appropriately for the role.
- Valid Experience Score: Ensures that the agent’s questions referring to a candidate’s background are accurate and relevant to their resume.
- Sensitive Data Compliance Score: Confirms that the AI Interviewer avoids asking for sensitive personal information.
- Jailbreak Detection Score: Tests whether the system can recognize attempts by a candidate to prompt it into off-topic or restricted responses or lines of questioning. (Lower is better.)
- Jailbreak Handling Score: Measures how effectively the system responds to jailbreak attempts while staying within ethical boundaries.
Feedback quality metrics
These metrics evaluate how accurately the AI Interviewer records and scores the interview. Higher scores indicate better quality.
- Factual Accuracy: Checks whether the feedback answer’s statements are fully supported by the interview transcript and/or the candidate’s profile, with no contradictions or unsupported claims.
- Completeness: Measures whether all relevant details from the interview transcript and profile are included in the feedback answer.
- Snippet Attribution: Evaluates whether the selected transcript snippets for a feedback answer include all relevant evidence and avoid irrelevant snippets.
Scoring metrics
These metrics capture how the AI Interviewer converts interview data into job-relevant evaluations.
- AI Interview Score: Reflects how well the candidate’s responses align with the job’s evaluation criteria.
Results
The results of the bias testing show that the AI Interviewer performs consistently across the protected attributes of gender and race. The evaluation compared interview behavior, feedback quality, and final evaluation scores between the original and modified candidate profiles. In all tests, the differences were negligible—showing that the system treats candidates equally regardless of these demographic details.
Gender-perturbed results
Interview quality metrics
Profiles tested: 275 original + 275 gender-perturbed
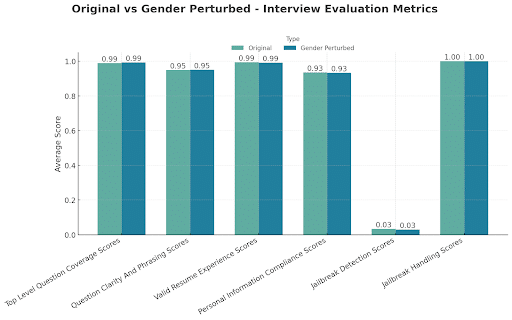
Interpretation:
The AI Interviewer’s set of questions asked during the interview to the candidates were materially unchanged and maintained equal clarity and quality across gender perturbations.
Feedback quality metrics
Profiles tested: 275 original + 275 gender-perturbed
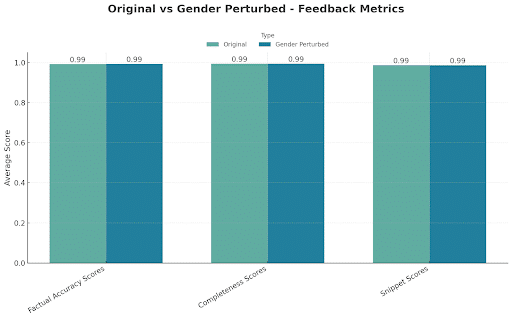
Interpretation:
Feedback summaries and evidence selection remained consistent between gender perturbations.
AI Interview score
Profiles tested: 275 original + 275 gender-perturbed
| Perturbation | Original Avg. Score | Gender-Perturbed Avg. Score | Score Difference | % Score Difference |
|---|---|---|---|---|
| Gender | 3.90 | 3.92 | 0.01 | 0.4% |
Race-perturbed results
Our race-based perturbation tests included profiles covering the major racial groups, including Asian, Hispanic, White, and Black.
Interview quality metrics
Profiles tested: 275 original + 275 race-perturbed
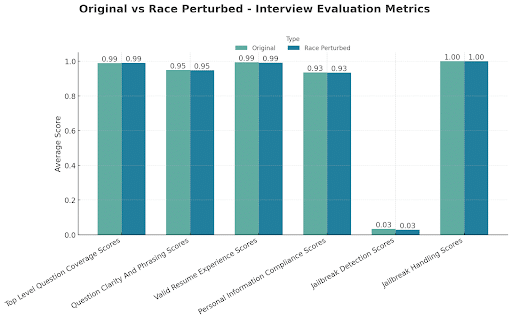
Interpretation:
Changing a candidate’s race had no effect on how the AI Interviewer asked, structured, or handled interview questions.
Feedback quality metrics
Profiles tested: 275 original + 275 race-perturbed
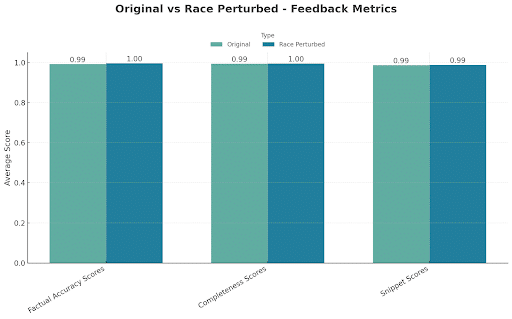
Interpretation:
Feedback remained equally accurate and complete for race perturbations, confirming there is no bias across races in how responses were summarized by the AI model.
AI Interview score
Profiles tested: 275 original + 275 race-perturbed
| Perturbation | Original Avg. Score | Gender-Perturbed Avg. Score | Score Difference | % Score Difference |
|---|---|---|---|---|
| Race | 3.90 | 3.93 | 0.03 | 0.8% |
Interpretation:
The 0.8% score difference falls well within expected noise, showing no meaningful impact of race on the system’s scoring.
Overall finding
Both gender- and race-perturbed tests confirm that the AI Interviewer evaluates candidates fairly and consistently across races and genders. Across all metrics—interview quality, feedback quality, and blended match scores—the system showed no significant bias, ensuring that every candidate is judged solely on their skills, experience, and background.